
Gさんが提供するVertex AI VisionAIを使用してみて。
2023.04.04
おはようございます。Vision AIで画像解析の精度を試しみた結果、これで良いかなと思い始めています。これを使用して「釣ったー」という釣り画像をシェアするサイトを作ろうかなって思っています。問題だったのが魚が写っている写真なのかを判別することが問題になっていました。当初はtensorflowで提供されている学習済みのモデルを使用したJSライブラリを使用して画像の判別しようと思っていたのですが、これ少し難がありモデルの精度がいまいちな所があります。
サービス提供する側としては、あまり変な画像をUPされるとその対応に時間を費やさないといけないので、そこは避けたい所があります。文章での誹謗中傷は現在、誹謗中傷に特化したデータを自分がもっているので、その方法を使用することである程度、投稿の判別は可能になっていましたが、前文で書いた通り画像の判別は難です。
今から魚のデータセットを取り入れたとしても、学習させるPCが存在しない。いつも使用しているPCでは、学習させることは可能だけどさて、どのぐらい時間を費やさないといけないのかなどの問題があるので断念。旧PCはあるにはあるのだけど機械学習させるスペックではないので断念した。
そのため機械学習モデル済みのモデルが必要になった。モデルを探すより、学習済みのAPIを使うのが手っ取り早いと思ったので、AWS、Azure、GCPという候補の中でざっくり考えた結果。
GCPに軍配が上がって、試してみた結果。良好だったのでそちらを使用することにした。
尚、VisualAPIを使用するにあたって参考にしたサイト。環境変数などの設定などは如何なものかと思ったのでそこは参考にしていない🙄。
・https://www.asobou.co.jp/blog/web/vision-api
・https://packagist.org/packages/google/cloud-vision
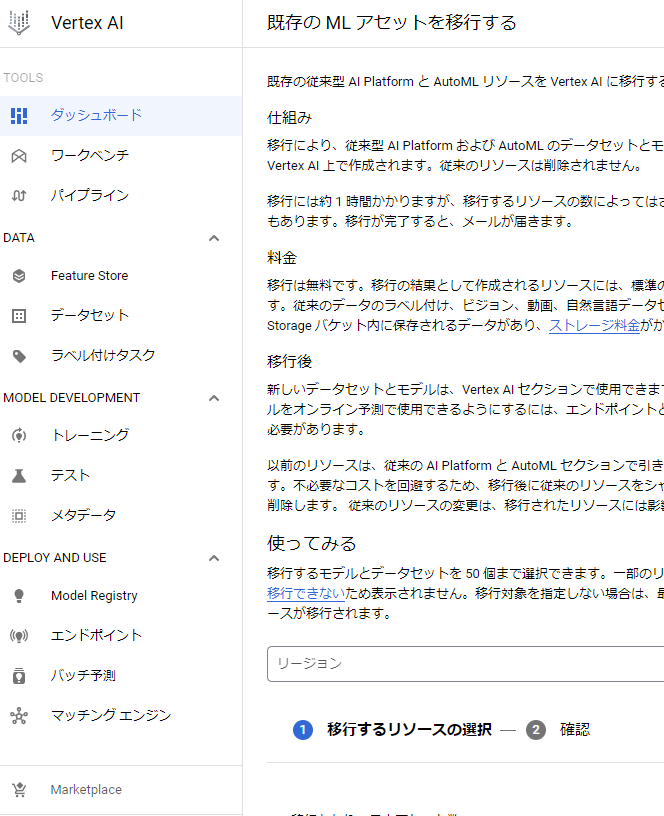
注意事項として画像をひとつ添付する。左の項目最下のマーケットプライスの中にVertex AI VisionAIが組み込まれているので、それを有効にすること。後は上記のリンクを参考にすると上手く出来ると思います。
タグ
AI VisionAI, API, AWS, Azure, GCP, JSライブラリ, tensorflow, Vertex, VisualAPI, スペック, マーケットプライス, 側, 判別, 前文, 断念, 環境変数, 精度, 誹謗中傷, 軍配, 難,

機械学習は学習するのにどれぐらいのデータが必要?
2022.09.06
今日は大荒れ☔との事です、おはようございます。
8月の半ばにとある事情で機械学習で人の顔かどうかを判別させるモデルをTensorFlowで作ってみたのですが、結果、学習のデータが少なかったのが原因なのか分からないけども・・・。人工無能と言いたくなるほど無能な機械学習が出来上がりました。犬の画像を見せてもこれは人ですと判定してくれるので正直、ホントげんなりでした。
画像分類の作り方は簡単です、学習したいディレクトリとテスト用のディレクトリを作り、それぞれの階層に分類ディレクトリを設置し、その中に学習の画像データとテスト用の画像データを入れてサンプルコードをちょちょっと修正してテンソル(Pythonを実行)で学習してもらうだけです。
尚、自分のテストデータは100枚ほどしかなかったので、全然駄目な結果になりましたが3000枚以上の画像データがあればちゃんとした判別が出来たのかも知れません。
スマホの顔認証は動画データを画像データー変換して学習させているのでしょうね。そうすれば数千枚の画像は生成出来ると思います。
例えばopencv-pythonなんかで画像変換するのが良さそうですよ。
pip install opencv-pythonタグ
100, 3000, 4, 8, Python, tensorflow, コード, これ, サンプル, ゼーロ, それぞれ, ちょ, データ, ディレクトリ, テスト, テンソル, どれぐらい, ヒーロー, ホント, モデル, 中, 事, 事情, 人, 人工, 今日, 作り方, 修正, 分類, 判別, 判定, 半ば, 原因, 器, 大荒れ, 学習, 実行, 必要, 機械, 正直, 無能, 犬, 画像, 簡単, 結果, 自分, 設置, 階層, 顔, 駄目,

Proofreading(校正)というリクルートが開発したAPIを使って。
2021.04.27
Proofreading(校正)というリクルートが開発したAPIを使って、今まで投稿した記事に誤字がないかを判別してもらった。因みに1000文字を超える文章は対象にならないのでワードプレスで取得した記事を900文字程度で切って判断してもらうことにしています。誤字があった場合、1を最大値として値が渡されるので、その平均値を取ればその文章の誤字率が判定できる。今回は平均値を取らず、最大値を判断材料として文章をスコア化しました。一応、判断した値をCSVで出力するプログラムをちょこちょこと制作したので参考にして頂ければ幸いです。正直なところ、ProofreadingのAPIが制度が良いのか疑わしいものがあるがAPIを取り扱うのが始めてという人は勉強になると思います?。
ソースコードはこちらになります。
<?php
require "../../wp-load.php";
global $wpdb;
$proofreading = function($text=""){
$url = "https://api.a3rt.recruit-tech.co.jp/proofreading/v2/typo";
$params = [
'apikey' => '取得したAPIKEY',
'sentence'=>"$text",
'sensitivity'=>"high"
];
$curl = curl_init($url);
curl_setopt($curl, CURLOPT_POST, TRUE);
curl_setopt($curl, CURLOPT_POSTFIELDS, $params);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($curl);
curl_close($curl);
$obj = (object)json_decode($response);
$score = 100;
if($obj->alerts){
$max = 0;
foreach($obj->alerts as $key=>$val){
$max = $max<$val->score?$val->score:$max;
}
$score = 100 - ($max * 100);
}
return $score;
};
if($argv[0]){
file_put_contents("blogscore.csv","");
$query = "SELECT * FROM $wpdb->posts WHERE post_status = 'publish' and post_type = 'post'";
$results = $wpdb->get_results( $wpdb->prepare($query));
foreach($results as $row) {
$id = $row->ID;
$title = $row->post_title;
$score = $proofreading(mb_strimwidth(preg_replace("/[\r|\n]/","",strip_tags($row->post_content)),0,900,"…"));
$str = "'$id'".",'".$title."',"."'$score'";
print $str.PHP_EOL;
file_put_contents("blogscore.csv",mb_convert_encoding($str."\n","SJIS","UTF-8"),FILE_APPEND);
}
}
タグ
1, 1000, 900, API, CSV, lt, php, Proofreading, quot, require, wp-load, コード, こちら, こと, スコア, ソース, ところ, プレス, プログラム, もの, リクルート, ワード, 人, 今回, 値, 出力, 判別, 判定, 判断, 制作, 制度, 勉強, 参考, 取得, 場合, 対象, 平均, 投稿, 文章, 最大, 材料, 校正, 正直, 記事, 誤字, 開発,
超それ!機械学習、 TensorFlow!!
2017.09.02

機械学習でどんな事出来るの?
勝手に勉強してくれるお利口さんな機械学習もあるけれど
オープンソースで提供している機械学習ってのは大体、前もって
答えを与えておいて、そこから判別するものがある。
今回、某検索サイトが提供しているTensorFlowでどんな事が出来るのだろうと
思い、ネットサーフィンしていたら、面白い記事を見つけました。
なんと、Raspberry PiとTensorflowをつかってきゅうりの仕分けができるというシステムを
開発した人がいました。この記事を読んでまさに「超それ!」
https://cloudplatform-jp.googleblog.com/2016/08/tensorflow_5.html
自分が思い描いていた機械学習でできることだと!
いやホントに凄いな、機械学習っていうのは
これからの花形になっていく存在だとつくづく思ってしまいました。
これか先、AIを作る層、AIライブラリやAI、APIを使う層、そしてAIを使う層に
別れていくだろうと思います。じぶんみたいな凡人開発者はAIを作る層には入れないですが、
AIライブラリやAI、APIなどを活用できるようにしないと、
今後、この業界で生き残っていくのは難しいじゃないかなと思っています。
なぜ、そう痛感しているのかと言えば
機械学習で検索すると数年前まではあまりヒットしなかったのに
去年あたりからな。いろいろな人が技術をオープンで公開し始めています。
この動きは止まることはないのではないかと思うのが一番の理由です。
ちなみに自分はあるサーバでTensorflowをインストールして動かしています。
まだ、テストを動かして遊んでいるぐらいで、じぶんでゴニョゴニョ開発しているわけではないです。
開発する前にやらないといけない事があるので、そちらが終わってから
Tensorflowコードをパクりながら学習しようかなと考えています。
https://www.youtube.com/watch?v=4HCE1P-m1l8
ちなみにtensorflowの公開をしますとか、言っていてからもう一年ぐらい
経過しているのかもしれません。すみません、じぶんは阿呆なので
もう少し理解するまでお時間が必要です。噛み砕いて提供できるまでには
結構、時間が必要かもしれません。
じぶんを機械学習したいこの頃でした・・・(´・ω・`)。
{kind=link}
タグ
08, 2016, 5, AI, API, cloudplatform-jp, com, googleblog, html, https, Pi, Raspberry, tensorflow, オープン, お利口, きゅうり, けが, こと, これ, サーフィン, サイト, システム, ソース, そこ, それ, ネット, ホント, もの, ライブラリ, 事, 人, 今回, 仕分, 先, 判別, 勉強, 勝手, 大体, 存在, 学習, 層, 提供, 検索, 機械, 答え, 自分, 花形, 記事, 開発,