
Line3.8bバージョンとline1.7b バージョン使ってみたけど何か。
2023.08.20
おはようございます、Line3.6bバージョンとline1.7b バージョン使ってみたけどエヌビディア(GPT)が入っていないと動かないだって、でもどうしても動かしたいと思っている方!CPUでも動かせるように変換してくれている人がいます。ありがたや~☺。
上記のURLへ移動して頂き、READMEを参照すればメモリが2Gあれば何とか最小のモデルが動かせるみたいです、ローカルで動かしたい方はエヌビディアさんのCUDA(Compute Unified Device Architecture)とCUDAツールキットも必要になります。あと、torch(pytorch)のバージョンとドライバが合っていないと上手く動かないようです。参考リンクはこちら👉https://qiita.com/nabenabe0928/items/7962dcf3030889667de4 https://pytorch.org/get-started/previous-versions/
なお、Windowsでは今のところ動かない可能性が高いですね(・・;)、ウブントゥとエヌビディアが最強ポッい。
タグ
Compute Unified Device Architecture, CPU, CUDA, CUDAツールキット, GPT, Line3.6bバージョン, pytorch, README, torch, url, Windows, ウブントゥ, エヌビディア, エヌビディアさん, ドライバ, バージョン, メモリ, モデル, 最小, 最強ポッい,

30万件のデータを扱っている方の話を聞いて一瞬😱となる。 #laravel #Queue #worker #jobs
2022.12.01
おはよう12月!!。皆さんおはようございます。今日から寒くなるそうですね。
先日、面談の中で30万件のデータを扱っている方の話を聞いて一瞬尻込みしましたが、自分でもその処理を捌くことが出来そうだなと思ったので、ダミーデータを作って今月中に捌いてみようと思います。なお、ローカルサーバーを使用して捌くのでレンタルサーバーやクラウドサーバーでメモリリークなんかで落ちたりしたらごめんなさい🙇。
因みに30万件のデーターをどう捌いているかといえば、非同期処理(Queue)で捌いているとの事。フレームワークはLaravelを使用し、非同期処理はララベルの機能であるキューを使用してバックエンドで処理を立ち上げているとの事。要は個々プロセス複数立ち上げて並列処理で動かすという事です、プロセスを立ち上げ過ぎたら、メモリ食いすぎてサーバー事態が落ちる可能性があるので別サーバーで動かすのが理想ぽっい、その場合はコネクションの設定してあげないといけない事やプロセスをどれぐらい立ち上がると良いのかなどの設定が必要みたいですね。
php artisan queue:table
php artisan migrateともあれ自分でダミーデータを用意して試してみないと感覚が掴めないし、実際上手くいくかなどが分からないので試してみます😳。
明日、1万件のダミーデーターを複製(コピペ)して30万件のエクセルファイル作る方法を記載します。
タグ
12, 30, jobs, Laravel, Queue, worker, エンド, キュー, クラウド, こと, サーバー, ダミー, データ, データー, バック, フレームワーク, プロセス, メモリ, ララベル, リーク, レンタル, ローカル, 一瞬, 万, 並列, 中, 事, 事態, 今日, 今月, 使用, 個々, 先日, 処理, 動, 可能性, 同期, 方, 機能, 皆さん, 自分, 複数, 要, 話, 面談,

staticかdynamicか、php-fpmの話。#php #apache
2022.11.01
おはようございます、メモリが肥大化して落ちました🤮。
先週の朝、メモリが肥大化して落ちてしまいました。今まではphp-fpmを1時間置きに再起動していましたが、それを変更した途端。メモリを食ってしまい落ちたわけです。
php-fpmの対応はこちらのサイトを参考にしました、尚、対応方法はそちらの記事を参照ください。その記事を読んでいて思ったことはやはりサーバーを増強したいということです。
でもVPSレンタルサーバーはサクサク表示させるには、結構お金がかかってしまいます、だったら固定IPを引いて自宅サーバーで運用した方が良いのかもしれないなってこの頃、思っています。
そうすればメモリはかなり詰めるし処理もそれなりに早くなります。恐らく瞬速で表示されるようになりますが、震災などが起きると忽ちダウンしてしまいますよね。
そう考えると・・・微妙ですね。
やはりVPSサーバーをもう一つ借りて調整するか、VPSサーバーと自宅サーバーを同期して運用するかだと…。
タグ
1, Apache, dynamic, IP, php, php-fpm, static, VPS, お金, かなり, こちら, こと, サーバー, サイト, そちら, それ, それなり, ダウン, はり, メモリ, もう一つ, レンタル, わけ, 借, 先週, 再起動, 処理, 参照, 参考, 固定, 増強, 変更, 対応, 微妙, 方, 方法, 朝, 瞬速, 自宅, 表示, 記事, 話, 途端, 運用, 震災, 頃,

東証システム障害の考察してみた。#東証システム障害考察
2020.10.02
7時4分にアラートが上がっていた?が、現場がアラートに気が付かず、後続の処理が流れ売上の前処理バッチ処理が走った時点なのかな。そこでようやく現場がアラートが出ていることに気づく、この時点でベンダーに現場が支持を仰いだのか、マニュアル通りフェイルオーバーしたんだろう。フェイルオーバーさせたけど失敗。メモリリークがおそらく原因でサーバーの切り替えが出来なかった。ここでベンダーに支持を仰いだ可能性もありそう。そしてベンダーがここらへんから介入して監視端末のログなどを調査したら、メモリリークのエラーログを確認したんだと思う。
※失敗したジョブがどこかに格納されるだろう?。フェイルオーバーさせるより後続の処理をストップさせて、ベンダーに支持を仰いだ方が良かったのかもしれないなと。でも現場は混乱していただろう。
メモリーリークが起きていたと思うと実際は前処理バッチ処理をして失敗していたんだろう。遮断して本日の東証での取引は出来ないようにしたのは正解だと思う。
メモリリークの原因は、メモリの物理的破損だったのでメモリが悪いと判断した。メモリエラーが監視端末のログにクリティカルなエラーとして表示されていたのかは不明だけど、おそらく見落としだと思う。
7時時点で相場や売上の前処理を取り込むのなら、何だか整合性がつきそうです。おそらく手動で前処理が走るのではなく全自動で前処理が走るシステムだったんだろう。従業員が端末の監視も7時からだったのかな?
資料が時系列で書かれていないので良く分からないけど、自分なりに東証システム障害を考察してみた。
現場のヒューマンエラーも疑われるけど、末端の従業員は下請け業者何だろうな?。ベンダーは常時、東証システムの現場にいたのか?とかいろいろな事が問われるかもしれないよな。
おそらく本日から正常に東証は取引できると思います。メモリを取っ替えだろうしメモリチェックもしているだろうし。
最後に頑張れ東証システムの現場!!
末端が解雇されないことを切に願う、これで直ぐに切られたら次の職には絶対につけなくなるよ。でも末端が悪いという事ならば数年後、数ヶ月後にはクビになる可能性は高いかもな。
ちなみに上記が昨日のツイートまとめになります。
タグ
4, 7, アラート, エラー, オーバー, ここ, ここら, こと, サーバー, システム, ジョブ, ストップ, バッチ, フェイル, べん, ベンダー, マニュアル, メモリ, メモリー, リーク, ログ, 介入, 処理, 前処理, 原因, 取引, 可能性, 失敗, 実際, 後続, 支持, 方, 時点, 本日, 東証, 格納, 気, 混乱, 現場, 監視, 確認, 端末, 考察, 調査, 遮断, 障害,
アマゾンウェブサービスってどうなの?
2018.01.17

アマゾンウェブサービスってどうなのか?
お安いのかお高いのかというのが自分が一番気になる所です。
試しに一度使ってみようかなと思ったことが
何度かありますが、どうも踏み切れないですよね。
セキュリティ対策などは結構簡単に対策を
取ることが出来るみたいなので便利だなと思う反面、
あまりにも機能が多いのでどれを使用すればよいのか、
迷います。おそらく最初はAmazon EC2を使用して
サーバ構築を行い、その後静的アドレスとドメインを結びつける事により
サーバ稼働するのだろうけれど、設定等を行うのが
正直なところ難儀だなと感じます。
サーバとの通信回線が早いので
応答速度はかなり改善するのではないかなと、
メモリは2Gぐらいが妥当かなとか・・・。
上記の設定などは自分でまぁ出来ます、SSLの設定も出来ますが
問題はお値段なんです、あまりにも月の値段が高ければ
やなんですよね。あとメールサーバーも構築しないと駄目なので
そこのところも難儀です。
ひとつのドメインではなく全てのドメインを引っ越すつもり。
これ以上、サーバ代を増やしたくないので出来れば
ひとつのサーバに集約化したいわけです。
そういう事を考えると安定して動いているXサーバで良いかなと
思ってしまうのですね。
「あぁどうしよう」orz
タグ
1, Amazon EC2, Amazon Web Services, Xサーバ, アマゾンウェブサービス, サーバ, サーバ代, サーバ構築, セキュリティ対策, ドメイン, ネットワーク, ひとつ, メールサーバー, メモリ, 何度か, 応答速度, 改訂版, 設定, 通信回線,
機械学習:ディープラーニング(TensorFlow)をインストールしてみた。
2017.03.24
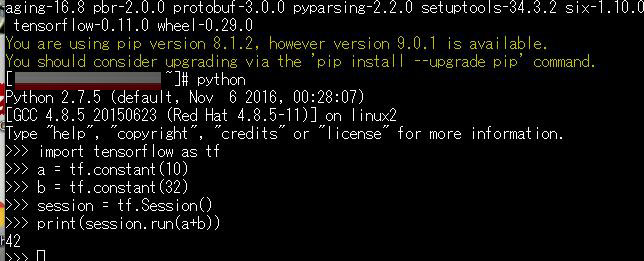
yum -y install python yum -y install python-pip python-dev python-virtualenv export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.11.0-cp27-none-linux_x86_64.whl pip install --upgrade $TF_BINARY_URL python -m tensorflow.models.image.mnist.convolutional
https://www.tensorflow.org/versions/r0.11/get_started/os_setup#using-pip
上記を参照に機械学習:ディープラーニング(TensorFlow)をインストールしてみてください。
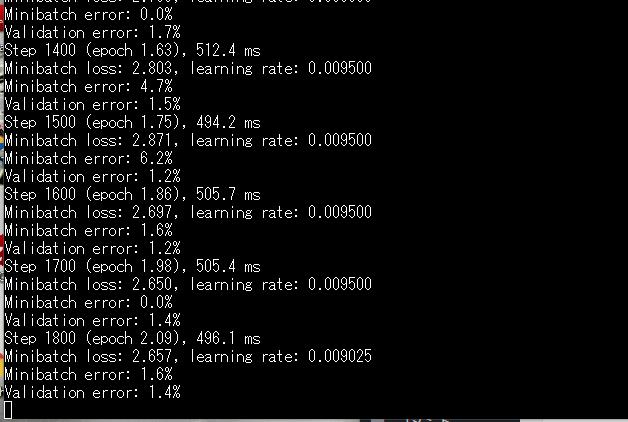
試しにイメージ学習(数字)をさせます。最初はエラー率が高いのですが徐々にエラー率が減っていきます。
自分はあまりメモリもCPUも積んでいない仮想サーバでしたが、何とか動きましたが
本気で機械学習をさせたい場合などは、それなりにCPUとメモリを積んでいないと
レンタルサーバー会社からサーバ負荷のため、停止させられる可能性がありますので
注意しないといけない点かもしれません。
学習後、数字の画像を与えるとで詰まるという方は、いろいろな本が出ているので
片っ端から読破するか、Netで調べるかになります。ちなみに今、じぶんは
片っ端から読破する方法を選びました。そこで気づいたのは、Pythonの言語を理解したほうが
良いということです。ノードが機械学習をする上で鍵になります!!
ということで?
時期を置いて続きを別記事として公開しますね。
!!(T_T)
https://github.com/tensorflow
{kind=link}
{kind=link}
タグ
AM, B01IT509EY, export TF_BINARY_URL, m tensorflow.models.image.mnist.convolutional, NextPublishing, pip install, y install python-pip python-dev python-virtualenv, yum, エラー率, サーバ負荷, ディープラーニング, ノード, メモリ, レンタルサーバー会社, 仮想サーバ, 別記事, 数字, 最新Googleマシンラーニング, 機械学習, 片っ端,
ワンコインでVPSが使用できるレンタルサーバーDTI!!
2017.03.14
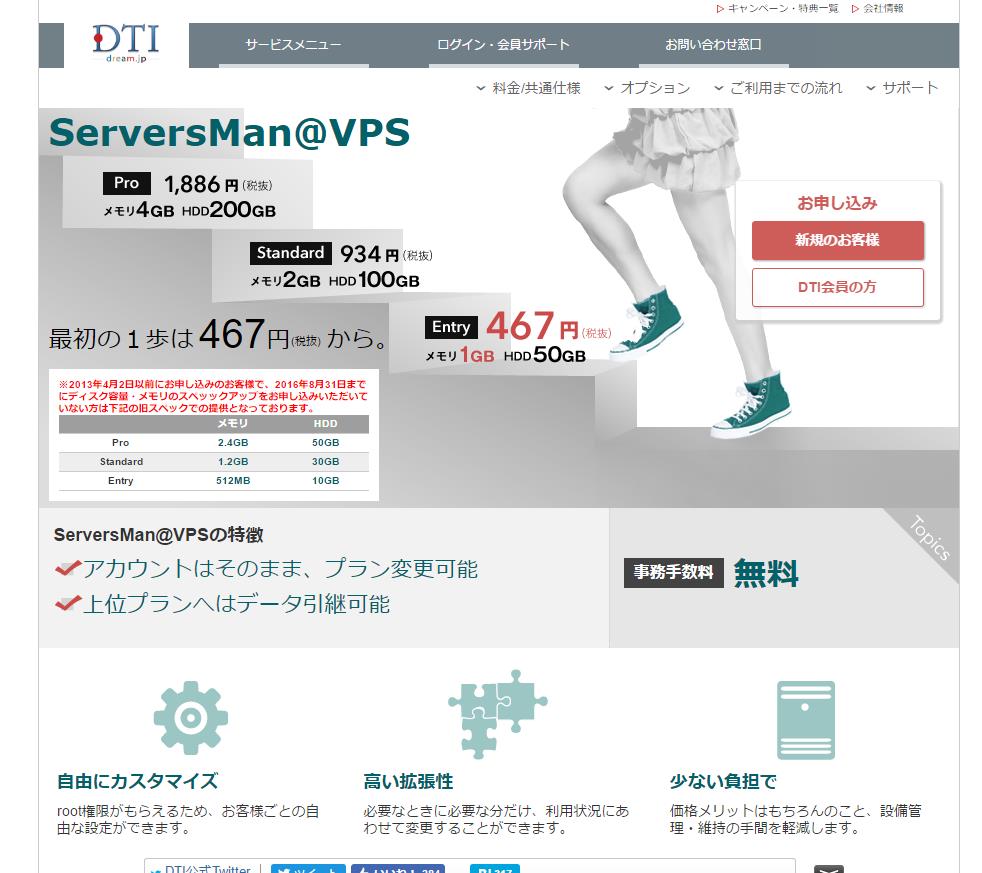
http://dream.jp/vps/
ワンコインでVPSが使用できるレンタルサーバーDTI!!
何気にすごいお得ださくらサーバーVPSやお名前.comのVPSサーバーが
有名だけど、メモリ1Gで月々467円って安いと思います。
ホントに安いな・・・損益分岐点になる人数を
知りたいな。たまに個人でサーバの切り売りしている強者も
いますが、こんな事を企業がやってしまうと太刀打ちできない
じゃないかとさえ思ってしまう。
値段はかなりお手頃価格なので
あとはレスポンスなどが気になるところですけど
実際、VPSで練習のためサーバを構築するのは
これで十分ですね。
タグ
CentOS 7, VPSサーバー, お名前, かなりお手頃価格, サーバー徹底構築, さくらサーバーVPS, メモリ, メモリ1G, レスポンス, レンタルサーバーDTI, ワンコイン, 人数, 何気, 実践, 強者, 損益分岐点, 月々467円,

クローラーするサービスの基礎。
2016.11.19
クローラーするサービスの基礎のソースを載せときます。殆どサイボウズ・ラボの人が書いたコードです。
このサンプルソースをそのまま貼り付けても一階層のリンクしか取得できません。
再帰処理の部分をコメントアウトしているからです。ちなみにコメントアウトを外してもメモリオーバーでおそらく
大体のサーバでエラーが出力されます。どうしたら良いのかといえば、DBに1階層目のリンクデータ、2階層目のリンクデータという様に保存する機能を施す。次にajaxで階層を受け渡しながら、再帰処理を行う。
再帰処理が終わる要素はそれ以上、下階層がないことを判断する。そのためには保存したデータを検索することが重要になる。=(イコール)
新規にデータを登録しているうちは、再帰処理を終わらせないようにすることが大事になる。
これの機能を加えることで巡回する事が可能になる。ここで注意しないといけないのが、外部リンクを保存しないことです。外部リンクまで保存していると巡回は永遠に終わらないでしょう・・・。
トイウコトデ
ほぼ??コピペソースを貼っときます。
<?php
echo json_encode($obj);
exit;
function get_linkarray($link)
{
$context = stream_context_create(array("http" => array("method" => "GET", "header" => "User-Agent: simplecrawler.library.php 0.0.1")));
$resultR = array();
$resultS = simplecrawler($context, $link, $link, parse_url($link));
foreach ($resultS as $k => $v) {
$resultR[] = $v;
}
return $resultR;
}
function simplecrawler($context, $link, $burl, $base, $linkArrayDat = array())
{
$linkArrayPre = crawler_link(crawler_page($link, $burl, $base, $context), $link, parse_url($link));
foreach ($linkArrayPre as $k => $v) {
if (!isset($linkArrayDat[$v])) {
$linkArrayDat[$v] = $v;
//$linkArrayDat = array_merge($linkArrayDat, simplecrawler($context, $v, $burl, $base, $linkArrayDat));
}
}
return $linkArrayDat;
}
function crawler_page($link, $burl, $base, $context)
{
if (strpos($link, $burl) === 0) {
$page = @file_get_contents($link, false, $context);
return $page === FALSE ? null : $page;
} else {
return null;
}
}
function crawler_link($page, $burl, $base)
{
$linkArray = array();
if ($page === null) {
return $linkArray;
}
preg_match_all("/[\s\n\t]+href\s?=\s?”(.*?)”/i", $page, $href);
for ($i = 0; $i < count($href[1]); $i++) {
$link = $href[1][$i];
if (preg_match("/^http(s)*\:\/\//", $link)) {
$result = $link;
} elseif (preg_match("/^\/.+$/", $link)) {
$result = $base["scheme"] . "://" . $base["host"] . $link;
} else {
// echo $base["path"] . “\n”;
$b = preg_split("/\//", dirname($base["path"]));
$t = preg_split("/\//", $link);
foreach ($t as $v) {
$l = $v === "." ? true : ($v === ".." ? array_pop($b) : array_push($b, $v));
}
$result = $base["scheme"] . "://" . $base["host"] . join("/", $b);
}
$linkArray[$result] = $result;
}
return $linkArray;
}
タグ
1, 2, ajax, db, アウト, イコール, うち, エラー, オーバー, クローラー, コード, ここ, こと, コメント, これ, サーバ, サービス, サイボウズ, サンプル, ソース, それ, ため, データ, トイウ, メモリ, ラボ, リンク, 一, 下, 事, 人, 保存, 再帰, 処理, 出力, 判断, 取得, 可能, 基礎, 外部, 大事, 大体, 巡回, 新規, 検索, 機能, 殆ど, 永遠, 注意, 登録, 要素, 部分, 重要, 階層,
CSVのデータ数万行とかをVBAでデータを加工するよりも
2016.05.30

CSVのデータ数万行とかをVBAでデータを加工するよりもPowerShellから加工するべし、、。
まず、いま勤めてる会社、WEB会社なんですが
WEBシステムに使うデータの加工をする機会が結構あったりします。
時には数万行とかのデータを取り込んで
加工することがあるですね。
今まで数万行のデータは分割して
処理をしていたのですが、PowerShellで取り込んで処理する
方法があるみたいなので、これからはソチラで
加工しようかなとか思っています。
ちなみにExcelやPHPだとMバイトのデータを
扱うと処理が落ちる場合が結構あります。
とくにPHPだとファイルをアップロードする場合や
扱えるメモリの設定により処理落ちする事は
多々あります。
なので、PHP側でどうしても
処理を行いたい場合は事前にファイルを分割するか、
処理する時点でshellなどを使いコマンドラインで
ファイルを分割するかなどの方法を
取らないといけないのです。
ファイルをアップロードする時点で
処理を行うか前もって処理を行なったデータを
SQLで読み込むかなど、いろいろな方法があります。
タグ
CSV, Excel, Mバイト, php, powershell, SQL, VBA, WEBシステム, コマンドライン, ソチラ, データ, データ数万行, ファイル, メモリ, 事前, 処理, 処理落ちする事, 加工, 方法, 時点,
Windows10が発表されました。正直、買う必要あるの?
2014.10.02
Windows10は正直、買う必要あるのか疑問です。散々、ユーザーから叩かれたWindows8を改善した結果、マイクロソフトのとった決断は原点回帰だったというオチです。ほぼ、Windows 7と同じユーザーインターフェイスです。機能はいろいろと変わってたりしますが、基本的にはWindows 7を高機能にしたという感じですね。ちなみに自分はWindows8からWindows8.1に変更し最近、Windows 7にダウングレードしました。 ちなみにWindows10は来年にリリースされるそうですよ。
そろそろパソコンも買い替えを考え中なのですけど…。メモリ(DDR4)の値段が落ち着くまで様子見な自分です。
https://www.youtube.com/watch?v=F_O-LrGL-YQ
タグ
1, DDR4, Windows 7, Windows10, Windows8, Windows8.1, オチ, ダウングレード, パソコン, マイクロソフト, メモリ, ユーザー, 値段, 原点, 正直, 決断, 疑問, 考え中, 買い替え, 高機能,